搜索引擎爬行过程详解(了解搜索引擎如何爬取网站信息)
 游客
2024-11-19 14:56:01
54
游客
2024-11-19 14:56:01
54
在现今信息化的社会中,搜索引擎已经成为人们获取信息的重要途径之一。而搜索引擎能够快速而准确地为用户提供所需信息,离不开搜索引擎的爬行技术。本文将为大家详细介绍搜索引擎的爬行过程及其相关内容,希望能对广大网站管理员和网络营销人员有所帮助。
")
爬虫是什么?
所谓爬虫,是指一种能够自动抓取网页并解析网页内容的程序。它是搜索引擎的一个重要组成部分,负责搜索引擎对互联网的全面覆盖。
如何进行网站的爬行?
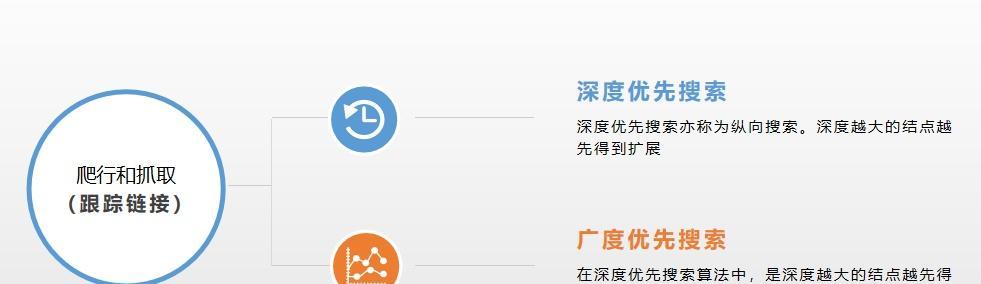
搜索引擎通过各种方式获取到网站的URL地址,然后根据网页链接依次抓取网页。每抓取一个页面,就会对这个页面中的所有链接进行提取,并递归抓取这些链接对应的页面。这样,搜索引擎就可以对整个互联网进行全面覆盖。
搜索引擎如何判断网站的重要性?
在搜索引擎的眼中,有一些网站比其他网站更重要。搜索引擎通过收集网页的链接数量、质量、内容质量等信息来评估网站的重要性。同时,搜索引擎还会考虑用户对该网站的反馈情况,例如用户访问时间、停留时间等。
搜索引擎爬行时的限制
为了防止恶意爬虫对网站的侵害,搜索引擎会设置一些爬行限制。这些限制包括爬虫抓取速度、抓取频率、抓取深度等。如果爬虫超出这些限制,就有可能被搜索引擎视为恶意爬虫而进行封禁处理。
搜索引擎如何处理robots.txt文件?
robots.txt是一个位于网站根目录下的文本文件,用于告诉搜索引擎哪些页面可以被访问,哪些页面不可以被访问。当搜索引擎抓取网站时,会首先查看robots.txt文件,遵循其中规定的访问限制。
如何让搜索引擎抓取到自己的网站?
如果想让搜索引擎尽快地抓取到自己的网站,可以通过提交网站地图的方式加快搜索引擎的抓取速度。同时,还可以通过增加外链等方式提高网站的重要性,从而更容易被搜索引擎抓取。
搜索引擎如何解析网页内容?
搜索引擎在爬取网页后,会对网页内容进行解析。它会从网页中提取出网页标题、关键词、描述等信息,然后将这些信息存储到数据库中以便用户进行检索。
搜索引擎如何对网站进行排名?
搜索引擎对网站进行排名时,会考虑多个因素,例如网站的重要性、链接数量、链接质量、内容质量、用户反馈等。通过对这些因素的评估,搜索引擎会将网站排名在搜索结果页面上。
如何优化网站排名?
为了让自己的网站在搜索引擎结果页面上排名更高,可以通过优化网站内容质量、外链质量等方式提高网站的重要性。同时,还可以通过选择恰当的关键词并进行SEO等方式优化网站排名。
如何防范黑帽SEO?
黑帽SEO是指一种违反搜索引擎规则、利用技术手段来提高网站排名的行为。为了防范黑帽SEO的发生,搜索引擎会不断更新自己的算法和规则,同时加强对恶意行为的打击力度。
搜索引擎如何保证搜索结果的准确性?
搜索引擎为了保证搜索结果的准确性,会不断优化自己的算法和规则。同时,还会依靠人工审核、反作弊技术等方式对搜索结果进行检测和筛选,确保用户可以获取到最优质的搜索结果。
搜索引擎爬行过程中的常见问题
在搜索引擎爬行过程中,可能会遇到各种问题,例如抓取失败、抓取频率过快等。为了应对这些问题,可以通过增加robots.txt限制、降低抓取频率等方式进行调整。
搜索引擎对移动端网站的处理方式
随着移动互联网的快速发展,搜索引擎也开始关注移动端网站的排名。为了更好地处理移动端网站,搜索引擎会根据移动设备的特点进行适配,并增加对移动端网站的抓取和排名。
搜索引擎爬虫与网络安全的关系
搜索引擎爬虫的存在也给网络安全带来了一些威胁。为了防范黑客利用搜索引擎爬虫来进行网络攻击,需要加强对搜索引擎爬虫的管理和控制。
搜索引擎的爬行技术是搜索引擎能够为用户提供准确、快速信息的重要保证。为了更好地优化网站排名,需要了解搜索引擎的爬行过程及其相关知识。希望本文能够对大家有所帮助!
搜索引擎爬行过程简介
随着互联网的不断发展,搜索引擎已经成为我们日常生活中必不可少的工具,而搜索引擎的排名也成为企业网站宣传和营销的重要手段。要提升网站的排名,就需要了解搜索引擎的爬行过程,下面就为大家介绍。
一、概述
搜索引擎爬行是指搜索引擎通过自己的程序自动访问互联网上的网页和网站,从中收集信息并保存到数据库中,以备用户检索时使用。
二、爬虫
爬虫是指搜索引擎的程序,它们会按照一定规则在互联网上遍历每个链接,并下载对应的HTML页面进行处理。
三、链接分析
爬虫会从一个页面开始,按照页面上的链接逐步向下进行爬行,每个页面上有多个链接,搜索引擎就会按照一定的算法对这些链接进行分析和排序。
四、规则文件
搜索引擎会根据规则文件来判断哪些页面可以被爬虫访问,哪些页面不能被访问。
五、robots.txt
robots.txt文件是一个文本文件,用于限制搜索引擎访问网站的页面。
六、页面源代码
搜索引擎爬虫会下载每个页面的源代码,根据代码中的标签和内容来判断页面的主题和内容。
七、关键字密度
搜索引擎爬虫会对页面中的关键字进行计算,根据计算结果来判断该页面的主题和相关度。
八、标题和描述
页面的标题和描述也是搜索引擎爬虫重要的判断依据之一,标题和描述需要包含关键字,并且要简明扼要地描述页面的内容。
九、图片和视频
搜索引擎爬虫也会对页面中的图片和视频进行处理和分析,从而确定页面的内容和主题。
十、外部链接
外部链接也是搜索引擎爬虫重要的判断依据之一,外部链接数量和质量都会影响网站的排名。
十一、更新频率
搜索引擎会根据网站更新频率来判断该网站的权重,更新频率越高,排名也越容易提升。
十二、网站结构
网站的结构也是搜索引擎爬行过程中需要考虑的因素之一,合理的网站结构可以提高爬虫的爬行效率。
十三、防爬虫技术
为了防止搜索引擎的爬虫对网站造成影响,一些网站会采用一些防爬虫技术,比如IP封禁、验证码等。
十四、黑帽SEO
一些企业会采用不正当手段来提高网站排名,这就是黑帽SEO,比如关键字堆砌、隐藏链接等。
十五、
搜索引擎爬行过程是一个复杂而又严谨的过程,如果想要优化网站排名,就需要遵守搜索引擎的规则,并根据规则来优化网站。只有了解搜索引擎爬行过程,才能更好地提升网站SEO关键字排名。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
转载请注明来自九九seo,本文标题:《搜索引擎爬行过程详解(了解搜索引擎如何爬取网站信息)》
标签:
- 上一篇: 抖音分红包详解(如何在抖音上分发红包赚钱)
- 下一篇: 抖音付费推广全攻略(打造品牌曝光的有效方式)

- 搜索
- 最新文章
- 热门文章
-
- 百度关键词SEO如何优化?提升搜索排名的技巧
- 搜索引擎优化SEO是什么意思?
- 百度网站优化排名如何提升?有效策略是什么?
- 搜索引擎优化SEO的最新趋势是什么?
- 网站排名优化的原理是什么?如何通过基础知识进行优化?
- 网站优化方案怎么制定?常见问题有哪些解决方法?
- 南县网站建设的费用是多少?南县网站建设需要多长时间?
- 长尾关键词是什么意思?如何利用长尾关键词提升SEO效果?
- 什么叫网站优化?网站优化的好处是什么?
- 龙口网站制作流程是怎样的?
- 提供网站制作服务时如何保证质量?
- SEO网站优化排名的要求是什么?如何满足这些要求以提升网站排名?
- SEO优化的核心是什么?如何有效提升网站排名?
- 企业SEO优化排名要怎样提升?提升策略和常见问题解答?
- 网站建设深圳有哪些优势?如何选择深圳网站建设服务?
- 如何管理SEO优化项目?项目管理中常见的问题是什么?
- SEO关键词如何优化?掌握这些技巧提升网站排名!
- 北京seo优化外包服务有哪些优势?如何选择合适的外包公司?
- 网站优化推广seo有哪些有效策略?
- 网站手机版排名seo怎么做?有哪些优化策略?
- 热门tag
- 标签列表
